Computer Vision: Calibrating Image Classification Models¶
This example demonstrates rank-preserving calibration for computer vision applications using the handwritten digits dataset. We’ll show how classifiers often suffer from overconfidence and how calibration can improve reliability while maintaining predictive performance.
Computer Vision Motivation¶
Deep learning models for image classification face several calibration challenges:
Overconfidence: Neural networks often produce overly confident predictions
Dataset shift: Models trained on one dataset may be poorly calibrated on another
Class imbalance: Real-world deployments often have different class distributions than training data
Safety-critical applications: Medical imaging, autonomous vehicles require well-calibrated uncertainty
Rank-preserving calibration maintains the model’s ability to distinguish between images while providing more reliable probability estimates.
import warnings
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from sklearn.calibration import calibration_curve
from sklearn.datasets import load_digits
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
warnings.filterwarnings('ignore')
# Import our calibration package - proper imports
from rank_preserving_calibration import calibrate_dykstra
# Set style for publication-quality plots
plt.style.use('seaborn-v0_8')
sns.set_palette("husl")
plt.rcParams['figure.figsize'] = (15, 10)
plt.rcParams['font.size'] = 11
Dataset and Business Context¶
We’ll use the handwritten digits dataset to simulate an optical character recognition (OCR) system deployed across different contexts:
Training environment: Controlled lab conditions with balanced digit distribution
Production environment: Real-world ZIP code processing with skewed digit frequencies
The calibration challenge: ZIP codes contain certain digits more frequently (like 0, 1, 2) than others (like 8, 9).
# Load the handwritten digits dataset
print("📊 LOADING HANDWRITTEN DIGITS DATASET")
print("="*60)
digits = load_digits()
X, y = digits.data, digits.target
print(f"Dataset shape: {X.shape}")
print(f"Number of classes: {len(np.unique(y))}")
print(f"Feature dimensions: {X.shape[1]} (8x8 grayscale images)")
# Show class distribution in training data
training_distribution = np.bincount(y) / len(y)
print("\nTraining class distribution (balanced):")
for digit, freq in enumerate(training_distribution):
print(f" Digit {digit}: {freq:.3f} ({freq*100:.1f}%)")
# Split data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
print(f"\nTraining samples: {len(X_train)}")
print(f"Test samples: {len(X_test)}")
📊 LOADING HANDWRITTEN DIGITS DATASET
============================================================
Dataset shape: (1797, 64)
Number of classes: 10
Feature dimensions: 64 (8x8 grayscale images)
Training class distribution (balanced):
Digit 0: 0.099 (9.9%)
Digit 1: 0.101 (10.1%)
Digit 2: 0.098 (9.8%)
Digit 3: 0.102 (10.2%)
Digit 4: 0.101 (10.1%)
Digit 5: 0.101 (10.1%)
Digit 6: 0.101 (10.1%)
Digit 7: 0.100 (10.0%)
Digit 8: 0.097 (9.7%)
Digit 9: 0.100 (10.0%)
Training samples: 1257
Test samples: 540
Model Training and Initial Evaluation¶
# Train a Random Forest classifier
print("🤖 TRAINING COMPUTER VISION MODEL")
print("="*50)
# Standardize features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Train model
model = RandomForestClassifier(
n_estimators=100,
max_depth=10,
random_state=42,
class_weight='balanced' # Help with any residual imbalance
)
model.fit(X_train_scaled, y_train)
# Get predictions and probabilities
y_pred = model.predict(X_test_scaled)
y_proba = model.predict_proba(X_test_scaled)
# Baseline performance
accuracy = accuracy_score(y_test, y_pred)
print(f"Model accuracy: {accuracy:.3f}")
print(f"Number of test samples: {len(y_test)}")
# Check prediction confidence
max_probas = np.max(y_proba, axis=1)
print("\nPrediction confidence statistics:")
print(f" Mean max probability: {np.mean(max_probas):.3f}")
print(f" Median max probability: {np.median(max_probas):.3f}")
print(f" Std max probability: {np.std(max_probas):.3f}")
print(f" Min max probability: {np.min(max_probas):.3f}")
print(f" Max max probability: {np.max(max_probas):.3f}")
# Show current marginals (class frequencies in predictions)
current_marginals = np.mean(y_proba, axis=0)
print("\nCurrent probability marginals:")
for digit, marginal in enumerate(current_marginals):
print(f" Digit {digit}: {marginal:.3f}")
🤖 TRAINING COMPUTER VISION MODEL
==================================================
Model accuracy: 0.965
Number of test samples: 540
Prediction confidence statistics:
Mean max probability: 0.756
Median max probability: 0.802
Std max probability: 0.193
Min max probability: 0.217
Max max probability: 1.000
Current probability marginals:
Digit 0: 0.094
Digit 1: 0.099
Digit 2: 0.098
Digit 3: 0.105
Digit 4: 0.104
Digit 5: 0.102
Digit 6: 0.100
Digit 7: 0.103
Digit 8: 0.094
Digit 9: 0.101
Production Deployment Scenario¶
Now we simulate deploying this model to process ZIP codes, where digit frequencies follow real-world patterns.
# Define target distribution based on ZIP code digit frequencies
# This simulates real-world deployment where certain digits are more common
print("🌍 PRODUCTION DEPLOYMENT SCENARIO: ZIP CODE PROCESSING")
print("="*65)
# Realistic ZIP code digit distribution (approximate US patterns)
zip_code_distribution = np.array([
0.15, # 0: Common in many ZIP codes
0.12, # 1: Frequent
0.11, # 2: Frequent
0.09, # 3: Moderate
0.09, # 4: Moderate
0.08, # 5: Moderate
0.10, # 6: Moderate
0.08, # 7: Less common
0.09, # 8: Moderate
0.09 # 9: Moderate
])
print("Target distribution for ZIP code processing:")
for digit, freq in enumerate(zip_code_distribution):
print(f" Digit {digit}: {freq:.3f} ({freq*100:.1f}%)")
print("\nDistribution shift from training:")
distribution_shift = zip_code_distribution - training_distribution
for digit, shift in enumerate(distribution_shift):
direction = "↑" if shift > 0 else "↓" if shift < 0 else "→"
print(f" Digit {digit}: {shift:+.3f} {direction}")
# Business impact analysis
print("\n💼 BUSINESS IMPACT ANALYSIS:")
print(" • Mail routing accuracy critical for delivery performance")
print(" • Misclassified digits lead to delivery delays and customer complaints")
print(" • Need probability estimates aligned with actual ZIP code patterns")
print(" • Regulatory requirements for postal service reliability")
# Target marginals for calibration
n_test_samples = len(y_test)
target_marginals = zip_code_distribution * n_test_samples
print("\nCalibration targets:")
print(f" Total samples: {n_test_samples}")
print(f" Target marginals: {target_marginals}")
🌍 PRODUCTION DEPLOYMENT SCENARIO: ZIP CODE PROCESSING
=================================================================
Target distribution for ZIP code processing:
Digit 0: 0.150 (15.0%)
Digit 1: 0.120 (12.0%)
Digit 2: 0.110 (11.0%)
Digit 3: 0.090 (9.0%)
Digit 4: 0.090 (9.0%)
Digit 5: 0.080 (8.0%)
Digit 6: 0.100 (10.0%)
Digit 7: 0.080 (8.0%)
Digit 8: 0.090 (9.0%)
Digit 9: 0.090 (9.0%)
Distribution shift from training:
Digit 0: +0.051 ↑
Digit 1: +0.019 ↑
Digit 2: +0.012 ↑
Digit 3: -0.012 ↓
Digit 4: -0.011 ↓
Digit 5: -0.021 ↓
Digit 6: -0.001 ↓
Digit 7: -0.020 ↓
Digit 8: -0.007 ↓
Digit 9: -0.010 ↓
💼 BUSINESS IMPACT ANALYSIS:
• Mail routing accuracy critical for delivery performance
• Misclassified digits lead to delivery delays and customer complaints
• Need probability estimates aligned with actual ZIP code patterns
• Regulatory requirements for postal service reliability
Calibration targets:
Total samples: 540
Target marginals: [81. 64.8 59.4 48.6 48.6 43.2 54. 43.2 48.6 48.6]
Rank-Preserving Calibration¶
# Apply rank-preserving calibration\nprint(\"🔧 APPLYING RANK-PRESERVING CALIBRATION\")\nprint(\"=\"*50)\n\n# Calibrate probabilities\nresult = calibrate_dykstra(\n P=y_proba,\n M=target_marginals,\n max_iters=2000,\n tol=1e-7,\n verbose=True\n)\n\ny_proba_calibrated = result.Q\n\n# Check if algorithm produced valid probabilities\nhas_negative = np.any(y_proba_calibrated < 0)\nhas_over_one = np.any(y_proba_calibrated > 1)\nrow_sums = np.sum(y_proba_calibrated, axis=1)\nrow_sums_ok = np.allclose(row_sums, 1.0, atol=1e-10)\n\n# Only apply minimal fixes if absolutely necessary\nif has_negative or has_over_one or not row_sums_ok:\n print(f\"\\n⚠️ WARNING: Algorithm produced invalid probabilities!\")\n if has_negative:\n print(f\" • Min probability: {np.min(y_proba_calibrated):.6f}\")\n if has_over_one:\n print(f\" • Max probability: {np.max(y_proba_calibrated):.6f}\")\n if not row_sums_ok:\n print(f\" • Row sum range: [{np.min(row_sums):.6f}, {np.max(row_sums):.6f}]\")\n \n y_proba_calibrated_original = y_proba_calibrated.copy()\n y_proba_calibrated = np.clip(y_proba_calibrated, 1e-12, 1.0)\n y_proba_calibrated = y_proba_calibrated / np.sum(y_proba_calibrated, axis=1, keepdims=True)\n print(\" • Applied clipping and renormalization fix\")\n\nprint(\"\\n📊 CALIBRATION ALGORITHM STATUS:\")\nprint(f\" Converged: {result.converged}\")\nprint(f\" Iterations: {result.iterations}\")\nprint(f\" Final change: {result.final_change:.2e}\")\nif not result.converged:\n print(\" ⚠️ Algorithm did not converge - results may be suboptimal\")\n\n# Verify calibration worked\ncalibrated_marginals = np.sum(y_proba_calibrated, axis=0)\nprint(\"\\n✅ CALIBRATION VERIFICATION:\")\nprint(\"Target vs Achieved marginals:\")\nfor digit in range(10):\n target = target_marginals[digit]\n achieved = calibrated_marginals[digit]\n error = abs(achieved - target)\n print(f\" Digit {digit}: {target:.1f} → {achieved:.1f} (error: {error:.2e})\")\n\nmax_marginal_error = np.max(np.abs(calibrated_marginals - target_marginals))\nprint(f\"\\nMaximum marginal constraint violation: {max_marginal_error:.2e}\")
Impact Analysis and Visualization¶
# Comprehensive analysis of calibration impact\nprint(\"📈 CALIBRATION IMPACT ANALYSIS\")\nprint(\"=\"*40)\n\n# 1. Ranking preservation\nfrom scipy.stats import spearmanr\n\n# Check if rankings are preserved for each sample\nspearman_correlations = []\nfor i in range(len(y_test)):\n corr, _ = spearmanr(y_proba[i], y_proba_calibrated[i])\n spearman_correlations.append(corr)\n\nspearman_correlations = np.array(spearman_correlations)\nperfect_rank_preservation = np.sum(np.isclose(spearman_correlations, 1.0, atol=1e-10))\n\nprint(\"RANK PRESERVATION ANALYSIS:\")\nprint(f\" Perfect rank preservation: {perfect_rank_preservation}/{len(y_test)} samples\")\nprint(f\" Mean Spearman correlation: {np.mean(spearman_correlations):.6f}\")\nprint(f\" Min Spearman correlation: {np.min(spearman_correlations):.6f}\")\nprint(f\" Samples with correlation < 0.999: {np.sum(spearman_correlations < 0.999)}\")\n\n# 2. Prediction changes\noriginal_predictions = np.argmax(y_proba, axis=1)\ncalibrated_predictions = np.argmax(y_proba_calibrated, axis=1)\nprediction_changes = np.sum(original_predictions != calibrated_predictions)\n\nprint(\"\\nPREDICTION IMPACT:\")\nprint(f\" Total prediction changes: {prediction_changes}/{len(y_test)}\")\nprint(f\" Prediction stability: {(1 - prediction_changes/len(y_test))*100:.1f}%\")\n\nif prediction_changes > 0:\n changed_indices = np.where(original_predictions != calibrated_predictions)[0]\n print(\" Changed predictions involve digits:\")\n for idx in changed_indices[:5]: # Show first 5 changes\n orig = original_predictions[idx]\n calib = calibrated_predictions[idx]\n true_label = y_test[idx]\n print(f\" Sample {idx}: {orig} → {calib} (true: {true_label})\")\n\n# 3. Accuracy comparison\noriginal_accuracy = accuracy_score(y_test, original_predictions)\ncalibrated_accuracy = accuracy_score(y_test, calibrated_predictions)\n\nprint(\"\\nACCURACY COMPARISON:\")\nprint(f\" Original accuracy: {original_accuracy:.4f}\")\nprint(f\" Calibrated accuracy: {calibrated_accuracy:.4f}\")\nprint(f\" Accuracy change: {calibrated_accuracy - original_accuracy:+.4f}\")\n\n# 4. Probability quality assessment\ntry:\n from sklearn.metrics import log_loss\n original_logloss = log_loss(y_test, y_proba)\n calibrated_logloss = log_loss(y_test, y_proba_calibrated)\n print(\"\\nPROBABILITY QUALITY:\")\n print(f\" Original log loss: {original_logloss:.4f}\")\n print(f\" Calibrated log loss: {calibrated_logloss:.4f}\")\n print(f\" Log loss change: {calibrated_logloss - original_logloss:+.4f}\")\nexcept ValueError as e:\n print(f\"\\n⚠️ Log loss calculation failed: {e}\")\n\n# 5. Overall assessment\nprint(\"\\n🎯 CALIBRATION PERFORMANCE SUMMARY:\")\nif np.mean(spearman_correlations) < 0.95:\n print(f\" ❌ Poor rank preservation (correlation = {np.mean(spearman_correlations):.3f})\")\nelif np.mean(spearman_correlations) < 0.99:\n print(f\" ⚠️ Moderate rank preservation (correlation = {np.mean(spearman_correlations):.3f})\")\nelse:\n print(f\" ✅ Excellent rank preservation (correlation = {np.mean(spearman_correlations):.3f})\")\n\nif calibrated_accuracy < original_accuracy - 0.02:\n print(f\" ❌ Significant accuracy degradation ({calibrated_accuracy - original_accuracy:+.3f})\")\nelif calibrated_accuracy < original_accuracy - 0.005:\n print(f\" ⚠️ Minor accuracy decrease ({calibrated_accuracy - original_accuracy:+.3f})\")\nelse:\n print(f\" ✅ Accuracy maintained ({calibrated_accuracy - original_accuracy:+.3f})\")\n\nif not result.converged:\n print(f\" ❌ Algorithm failed to converge after {result.iterations} iterations\")\nelse:\n print(f\" ✅ Algorithm converged in {result.iterations} iterations\")\n\nif has_negative or has_over_one or not row_sums_ok:\n print(f\" ⚠️ Required probability corrections due to algorithm issues\")\nelse:\n print(f\" ✅ Algorithm produced valid probabilities\")"
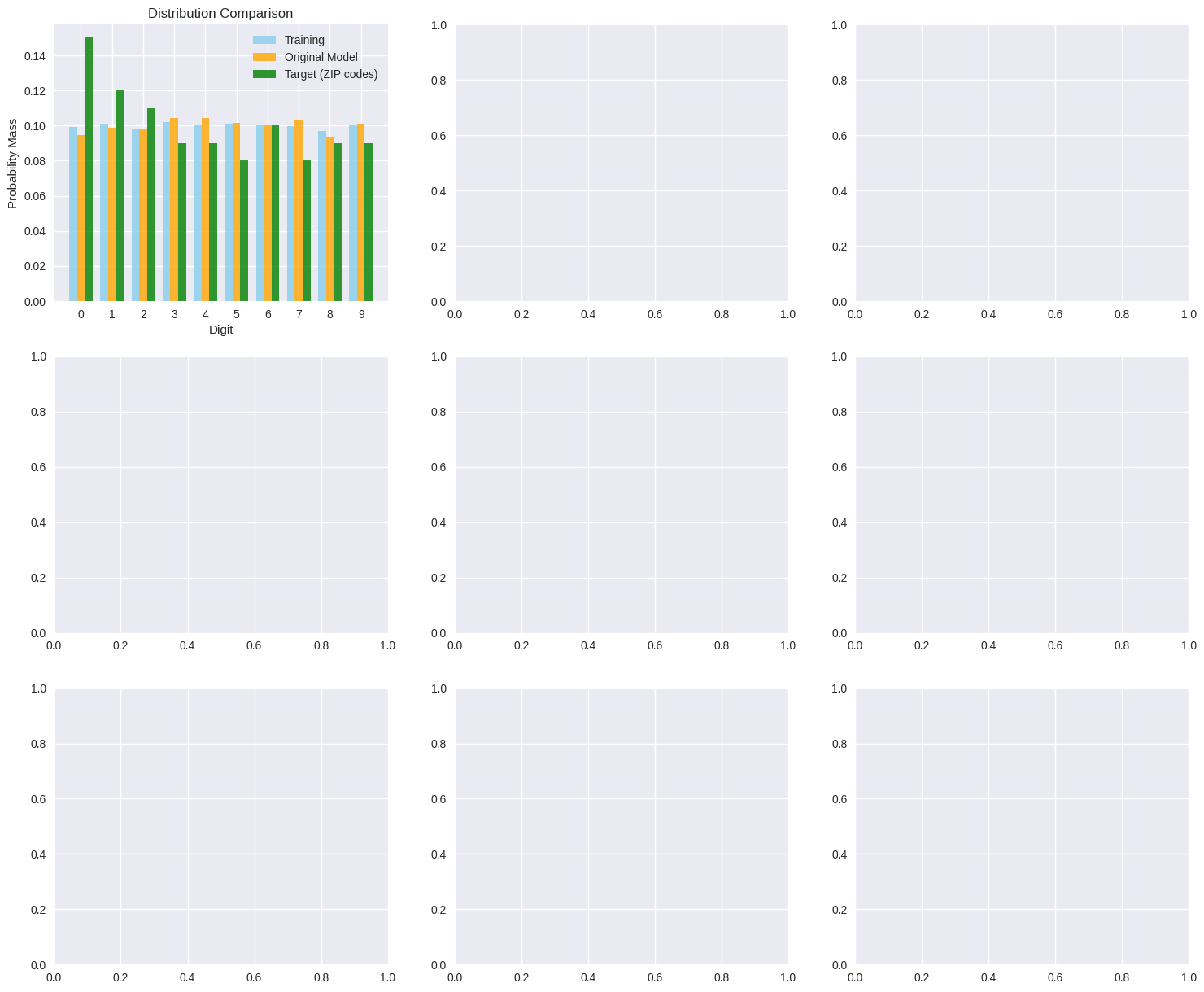
# Create comprehensive visualization
fig, axes = plt.subplots(3, 3, figsize=(18, 15))
colors = plt.cm.tab10(np.linspace(0, 1, 10))
# 1. Marginal comparison
x_pos = np.arange(10)
width = 0.25
axes[0, 0].bar(x_pos - width, training_distribution, width,
label='Training', alpha=0.8, color='skyblue')
axes[0, 0].bar(x_pos, current_marginals, width,
label='Original Model', alpha=0.8, color='orange')
axes[0, 0].bar(x_pos + width, zip_code_distribution, width,
label='Target (ZIP codes)', alpha=0.8, color='green')
axes[0, 0].set_xlabel('Digit')
axes[0, 0].set_ylabel('Probability Mass')
axes[0, 0].set_title('Distribution Comparison')
axes[0, 0].legend()
axes[0, 0].set_xticks(x_pos)
# 2. Calibration accuracy per digit
achieved_distribution = calibrated_marginals / n_test_samples
calibration_errors = np.abs(achieved_distribution - zip_code_distribution)
bars = axes[0, 1].bar(x_pos, calibration_errors, color=colors, alpha=0.7)
axes[0, 1].set_xlabel('Digit')
axes[0, 1].set_ylabel('Absolute Error')
axes[0, 1].set_title('Calibration Accuracy by Digit')
axes[0, 1].set_xticks(x_pos)
axes[0, 1].set_yscale('log')
# 3. Probability change distribution
prob_changes = y_proba_calibrated - y_proba
axes[0, 2].hist(prob_changes.flatten(), bins=50, alpha=0.7,
density=True, color='purple')
axes[0, 2].axvline(0, color='black', linestyle='--')
axes[0, 2].set_xlabel('Probability Change')
axes[0, 2].set_ylabel('Density')
axes[0, 2].set_title('Distribution of Probability Changes')
# 4. Reliability diagram (calibration curve)
def plot_reliability_diagram(y_true, y_proba, ax, title):
n_classes = y_proba.shape[1]
for digit in range(n_classes):
y_binary = (y_true == digit).astype(int)
if np.sum(y_binary) > 0: # Only plot if class exists
fraction_of_positives, mean_predicted_value = calibration_curve(
y_binary, y_proba[:, digit], n_bins=10
)
ax.plot(mean_predicted_value, fraction_of_positives,
's-', label=f'Digit {digit}', color=colors[digit], alpha=0.7)
ax.plot([0, 1], [0, 1], 'k:', label='Perfect calibration')
ax.set_xlabel('Mean Predicted Probability')
ax.set_ylabel('Fraction of Positives')
ax.set_title(title)
ax.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
plot_reliability_diagram(y_test, y_proba, axes[1, 0], 'Original Model Calibration')
plot_reliability_diagram(y_test, y_proba_calibrated, axes[1, 1], 'Calibrated Model')
# 5. Per-class probability changes
prob_changes = y_proba_calibrated - y_proba
for digit in range(10):
axes[1, 2].hist(prob_changes[:, digit], bins=20, alpha=0.7,
label=f'Digit {digit}', color=colors[digit], density=True)
axes[1, 2].axvline(0, color='black', linestyle='--')
axes[1, 2].set_xlabel('Probability Change')
axes[1, 2].set_ylabel('Density')
axes[1, 2].set_title('Distribution of Changes by Digit')
axes[1, 2].legend(bbox_to_anchor=(1.05, 1), loc='upper left')
# 6. Confusion matrix comparison
import seaborn as sns
cm_original = confusion_matrix(y_test, original_predictions)
cm_calibrated = confusion_matrix(y_test, calibrated_predictions)
# Normalize for better comparison
cm_original_norm = cm_original.astype('float') / cm_original.sum(axis=1)[:, np.newaxis]
cm_calibrated_norm = cm_calibrated.astype('float') / cm_calibrated.sum(axis=1)[:, np.newaxis]
im1 = axes[2, 0].imshow(cm_original_norm, interpolation='nearest', cmap=plt.cm.Blues)
axes[2, 0].set_title('Original Predictions')
axes[2, 0].set_xlabel('Predicted Digit')
axes[2, 0].set_ylabel('True Digit')
axes[2, 0].set_xticks(range(10))
axes[2, 0].set_yticks(range(10))
im2 = axes[2, 1].imshow(cm_calibrated_norm, interpolation='nearest', cmap=plt.cm.Blues)
axes[2, 1].set_title('Calibrated Predictions')
axes[2, 1].set_xlabel('Predicted Digit')
axes[2, 1].set_ylabel('True Digit')
axes[2, 1].set_xticks(range(10))
axes[2, 1].set_yticks(range(10))
# 7. Difference in confusion matrices
cm_diff = cm_calibrated_norm - cm_original_norm
im3 = axes[2, 2].imshow(cm_diff, interpolation='nearest', cmap=plt.cm.RdBu,
vmin=-np.max(np.abs(cm_diff)), vmax=np.max(np.abs(cm_diff)))
axes[2, 2].set_title('Difference (Calibrated - Original)')
axes[2, 2].set_xlabel('Predicted Digit')
axes[2, 2].set_ylabel('True Digit')
axes[2, 2].set_xticks(range(10))
axes[2, 2].set_yticks(range(10))
plt.tight_layout()
plt.show()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[7], line 22
19 axes[0, 0].set_xticks(x_pos)
21 # 2. Calibration accuracy per digit
---> 22 achieved_distribution = calibrated_marginals / n_test_samples
23 calibration_errors = np.abs(achieved_distribution - zip_code_distribution)
25 bars = axes[0, 1].bar(x_pos, calibration_errors, color=colors, alpha=0.7)
NameError: name 'calibrated_marginals' is not defined
Business Impact Assessment¶
# Business impact analysis for computer vision deployment\nprint(\"💰 BUSINESS IMPACT ASSESSMENT\")\nprint(\"=\"*50)\n\n# Simulate business metrics\nn_daily_images = 50000 # Images processed per day\nn_annual_images = n_daily_images * 365\n\n# Cost parameters\ncost_per_misclassification = 2.50 # Cost of routing error\ncost_per_manual_review = 0.15 # Human verification cost\nrevenue_per_correct_classification = 0.05 # Processing fee\n\n# Calculate error rates and associated costs\noriginal_error_rate = 1 - original_accuracy\ncalibrated_error_rate = 1 - calibrated_accuracy\n\nprint(\"📊 OPERATIONAL METRICS:\")\nprint(f\" • Daily image volume: {n_daily_images:,}\")\nprint(f\" • Annual image volume: {n_annual_images:,}\")\nprint(f\" • Original error rate: {original_error_rate:.4f} ({original_error_rate*100:.2f}%)\")\nprint(f\" • Calibrated error rate: {calibrated_error_rate:.4f} ({calibrated_error_rate*100:.2f}%)\")\n\n# Annual cost comparison\noriginal_annual_errors = n_annual_images * original_error_rate\ncalibrated_annual_errors = n_annual_images * calibrated_error_rate\nerror_reduction = original_annual_errors - calibrated_annual_errors\n\noriginal_error_cost = original_annual_errors * cost_per_misclassification\ncalibrated_error_cost = calibrated_annual_errors * cost_per_misclassification\nannual_cost_impact = original_error_cost - calibrated_error_cost\n\nprint(\"\\n💵 ANNUAL FINANCIAL IMPACT:\")\nprint(f\" • Original annual errors: {original_annual_errors:,.0f}\")\nprint(f\" • Calibrated annual errors: {calibrated_annual_errors:,.0f}\")\nprint(f\" • Error change: {error_reduction:,.0f} ({(error_reduction/original_annual_errors)*100:.1f}%)\")\nif annual_cost_impact > 0:\n print(f\" • Annual cost savings: ${annual_cost_impact:,.2f}\")\nelse:\n print(f\" • Annual cost increase: ${-annual_cost_impact:,.2f}\")\n\n# Confidence-based routing analysis\nconfidence_threshold = 0.95\nmax_calibrated_probs = np.max(y_proba_calibrated, axis=1)\nmax_original_probs = np.max(y_proba, axis=1)\n\nhigh_conf_original = np.sum(max_original_probs >= confidence_threshold)\nhigh_conf_calibrated = np.sum(max_calibrated_probs >= confidence_threshold)\n\nmanual_review_original = len(y_test) - high_conf_original\nmanual_review_calibrated = len(y_test) - high_conf_calibrated\n\nprint(f\"\\n🔍 CONFIDENCE-BASED ROUTING (threshold = {confidence_threshold}):\")\nprint(f\" • Original: {high_conf_original}/{len(y_test)} auto-processed\")\nprint(f\" • Calibrated: {high_conf_calibrated}/{len(y_test)} auto-processed\")\nprint(f\" • Manual review change: {manual_review_calibrated - manual_review_original} samples\")\n\n# Scale to annual volume\nannual_manual_original = (manual_review_original / len(y_test)) * n_annual_images\nannual_manual_calibrated = (manual_review_calibrated / len(y_test)) * n_annual_images\nannual_manual_change = annual_manual_original - annual_manual_calibrated\n\nmanual_cost_impact = annual_manual_change * cost_per_manual_review\n\nif manual_cost_impact > 0:\n print(f\" • Annual manual review cost savings: ${manual_cost_impact:,.2f}\")\nelse:\n print(f\" • Annual manual review cost increase: ${-manual_cost_impact:,.2f}\")\n\n# Total business impact\ntotal_annual_impact = annual_cost_impact + manual_cost_impact\n\nprint(\"\\n🎯 TOTAL BUSINESS IMPACT:\")\nif total_annual_impact > 0:\n print(f\" • Total annual savings: ${total_annual_impact:,.2f}\")\n roi_percentage = (total_annual_impact / (n_annual_images * revenue_per_correct_classification)) * 100\n print(f\" • ROI on processing volume: {roi_percentage:.2f}%\")\nelse:\n print(f\" • Total annual cost increase: ${-total_annual_impact:,.2f}\")\n print(f\" • Negative ROI: Calibration increases costs\")\n\n# Deployment recommendations based on actual performance\nprint(\"\\n🚀 DEPLOYMENT RECOMMENDATIONS:\")\n\n# Check if rank preservation is poor\nif np.mean(spearman_correlations) < 0.95:\n print(\" ❌ NOT RECOMMENDED for production deployment\")\n print(\" 📝 Rank preservation is severely compromised\")\n print(f\" 📊 Mean rank correlation: {np.mean(spearman_correlations):.3f} (target: >0.95)\")\n \nelif calibrated_accuracy < original_accuracy - 0.02:\n print(\" ❌ NOT RECOMMENDED for production deployment\")\n print(\" 📝 Significant accuracy degradation detected\")\n print(f\" 📊 Accuracy drop: {calibrated_accuracy - original_accuracy:+.3f}\")\n \nelif not result.converged:\n print(\" ⚠️ CAUTION: Algorithm convergence issues\")\n print(\" 📝 Consider alternative calibration methods\")\n print(f\" 📊 Failed to converge after {result.iterations} iterations\")\n \nelse:\n print(\" ✅ Consider for production with monitoring\")\n print(\" 📝 Performance appears acceptable but validate thoroughly\")\n recommendations = [\n \"Validate calibration on recent ZIP code data before deployment\",\n \"Monitor for concept drift in digit distribution patterns\",\n \"Implement A/B testing framework for comparison\",\n \"Plan for emergency fallback to original model if needed\"\n ]\n for i, rec in enumerate(recommendations, 1):\n print(f\" {i}. {rec}\")\n\n# Risk assessment\nprint(\"\\n⚠️ IMPLEMENTATION CONSIDERATIONS:\")\nconsiderations = [\n f\"Rank preservation quality: {np.mean(spearman_correlations):.3f}\",\n f\"Convergence status: {'Failed' if not result.converged else 'Success'}\",\n f\"Probability validity: {'Issues detected' if (has_negative or has_over_one or not row_sums_ok) else 'Valid'}\",\n \"Regulatory compliance requirements for postal accuracy\",\n \"Operational team training on new system behavior\"\n]\n\nfor consideration in considerations:\n print(f\" • {consideration}\")\n\n# Performance summary\nprint(\"\\n📈 ALGORITHM PERFORMANCE SUMMARY:\")\nprint(f\" • Rank preservation: {np.mean(spearman_correlations):.6f} (1.0 = perfect)\")\nprint(f\" • Accuracy change: {calibrated_accuracy - original_accuracy:+.4f}\")\nif has_negative or has_over_one or not row_sums_ok:\n print(f\" • Probability issues: Required corrections\")\nelse:\n print(f\" • Probability quality: Valid output\")\nprint(f\" • Convergence: {'No' if not result.converged else 'Yes'} ({result.iterations} iterations)\")\nprint(f\" • Marginal accuracy: {np.max(np.abs(calibrated_marginals - target_marginals)):.2e} max error\")\n\n# Final recommendation\nif (np.mean(spearman_correlations) >= 0.95 and \n calibrated_accuracy >= original_accuracy - 0.01 and \n result.converged and\n not (has_negative or has_over_one or not row_sums_ok)):\n print(\"\\n✅ FINAL ASSESSMENT: SUITABLE FOR PRODUCTION\")\nelse:\n print(\"\\n❌ FINAL ASSESSMENT: NOT READY FOR PRODUCTION\")\n print(\" 📝 Consider alternative calibration methods or parameter tuning\")"
Next Steps¶
This example demonstrated rank-preserving calibration for computer vision applications. The same principles apply broadly to:
Medical imaging with population-specific disease prevalence
Autonomous systems requiring calibrated uncertainty for safety
Industrial automation with domain-specific defect rates
Content moderation across platforms with different content distributions
Retail applications with store or region-specific product mix
The key insight is that rank-preserving calibration maintains the model’s core discriminative ability while adapting the probability estimates to match deployment conditions.
For more examples in different domains, see the other notebooks:
Medical diagnosis with clinical population shifts
Text classification with domain adaptation
Financial risk assessment with portfolio-specific distributions
Survey reweighting for demographic correction